
Pessimistic vs Optimistic Locking in PostgreSQL
I learned this the hard way. You don't have to.


What happens when two users try to buy the last item at exactly the same time? Not one after the other, simultaneously. Same millisecond, same row, same database. If you don’t have a clear answer to that question, your system probably has a bug you haven’t found yet.
Here’s the hard truth nobody tells you early enough: correct logic is not the same as correct behaviour under concurrency. You can write perfectly valid code, pass every test, deploy with confidence, and still ship a system that loses money, oversells inventory, or double-books seats at scale. The fix is locking. Here’s how it works.
Scene 1: Black Friday
It’s 12:00 AM. Your flash sale goes live. A limited-edition sneaker, only 50 pairs left. Within seconds, 4,000 users hit Buy Now simultaneously. Your server handles the load. Payments go through. Everyone gets a confirmation email.
Your inventory? It reads -312.
Scene 2: The Last Seat
Two users are booking tickets to a sold-out concert. One seat remains. Both see it as available. Both click Confirm at the same moment. Both get a booking confirmation. Both show up on the night, and only one gets in.
Scene 3: The Vanishing Money
A user has $500 in their account. Two withdrawal requests hit your API at exactly the same time: one for $400, one for $300. Both read the balance as $500. Both pass the validation check. Both write back their result. Your user just withdrew $700 from a $500 account.
Three different systems. Three different companies. One root cause: a race condition in the database. And the fix: optimistic or pessimistic locking: is something every backend developer needs to understand cold.
When I first read about these scenarios, my immediate thought was: wait, how does this even happen? The code looks fine. The logic is correct. How does a validated transaction end up negative? That question is exactly where the learning starts.
The Root Problem: What Is a Race Condition?
A race condition happens when two or more operations read the same data, make a decision based on it, then write back, without knowing the other operation is doing the same thing at the same time.
Here’s what it looks like at the database level with two concurrent transactions:
Time Transaction A (User 1) Transaction B (User 2)
----- ---------------------------- ----------------------------
T1 READ balance → $500 READ balance → $500
T2 balance - $400 = $100 balance - $300 = $200
T3 WRITE balance = $100 WRITE balance = $200
T4 ← B wins. $400 withdrawal lost.
Final balance: $200 (should be: $100 if both succeed, or one should fail)
This is called a lost update: one write silently overwrites another. Your ORM won’t warn you. Your application logs look clean. Your tests probably don’t catch it because tests rarely simulate true concurrency. It shows up in production, at scale, at the worst possible time.
Your ORM is hiding this problem from you. It manages queries beautifully, but it has no opinion on whether the data you just read is still valid when you write it back.
There are two battle-tested strategies to solve this: Pessimistic Locking and Optimistic Locking.
Pessimistic Locking: Lock First, Ask Questions Later
The name threw me off at first. Pessimistic? It sounds like a personality flaw. But the logic clicked once I thought about it as a policy: assume the worst, protect accordingly.
Pessimistic locking operates on a simple assumption: conflicts are likely, so prevent them before they can happen. You lock the row at read time, do your work, then release the lock when you’re done. No one else can touch that row until you’re finished.

How It Works in PostgreSQL
PostgreSQL implements pessimistic locking via SELECT ... FOR UPDATE:
BEGIN;
-- Lock the row immediately on read
SELECT * FROM accounts WHERE id = 1 FOR UPDATE;
-- Any other transaction trying to SELECT...FOR UPDATE
-- on this row will BLOCK here until we commit.
UPDATE accounts SET balance = balance - 400 WHERE id = 1;
COMMIT; -- Lock is released
Lock Mode Variants
PostgreSQL gives you four lock modes, from strongest to weakest:
FOR UPDATE -- Blocks all reads (FOR SHARE) and writes
FOR NO KEY UPDATE -- Blocks writes, allows FOR SHARE reads
FOR SHARE -- Allows others to also FOR SHARE, blocks writes
FOR KEY SHARE -- Weakest: only blocks FOR UPDATEFor most financial or inventory use cases, FOR UPDATE is what you want. Use the lighter modes only when you’ve deliberately profiled and need to reduce contention.
SKIP LOCKED: The Secret Weapon for Job Queues
One of PostgreSQL’s most useful features for pessimistic locking is SKIP LOCKED. Instead of waiting for a locked row, it skips it and moves to the next available one. This is perfect for worker queues:
-- Worker picks up the next available job, skipping locked ones
SELECT * FROM jobs
WHERE status = 'pending'
ORDER BY created_at
LIMIT 1
FOR UPDATE SKIP LOCKED;Ten workers can run this query simultaneously, and each will grab a different row without blocking each other. It’s elegant, efficient, and completely avoids the deadlock risk of competing for the same row.
The Pitfalls
Pessimistic locking is powerful but comes with real costs. First, reduced throughput: while one transaction holds a lock, everyone else waits. At high concurrency, this creates a queue that can cascade into timeouts. Second, deadlocks: if Transaction A locks row 1 then tries to lock row 2, while Transaction B has locked row 2 and wants row 1, both will wait forever. PostgreSQL detects this and kills one of them, but your application needs to handle that error and retry.
Rule of thumb: keep pessimistically locked transactions as short as possible. Read, act, write, commit. Never do slow operations (API calls, heavy computation) while holding a lock.
Real-World Usage: Who Uses Pessimistic Locking and Why
Pessimistic locking isn’t a niche pattern: it’s the backbone of systems where wrong data has real-world consequences.
Banking and Payment Systems
Every major bank uses pessimistic locking on account balance rows. When you initiate a wire transfer, the source account is locked for the duration of the transaction. No other debit or credit can touch that row until the transfer either commits or rolls back. The cost in throughput is completely acceptable: a user’s account is not a high-contention row. But correctness is everything. An overdraft caused by a race condition isn’t a UX bug, it’s a regulatory incident.
Airline and Concert Ticketing
Seat reservation systems lock a seat row the moment a user enters the payment flow: not when they complete it. This is often called a ‘hold’ and has a timeout (if you don’t complete payment in 10 minutes, the lock releases). Under the hood, this is pessimistic locking with a TTL managed by the application. Ticketmaster, for example, holds seats during checkout to prevent two users from completing payment on the same seat simultaneously.
Inventory Management in Flash Sales
When a product has limited stock and demand spikes (a limited sneaker drop, a games console launch), pessimistic locking on the inventory row prevents overselling. Shopify’s infrastructure, for instance, uses database-level row locking on inventory during checkout for high-demand products, because under true concurrent load, optimistic locking’s retry storm would make the system slower and still potentially incorrect.
Job and Task Queues
Any system where multiple workers pull tasks from a shared queue (email sending, report generation, order processing) uses pessimistic locking with SKIP LOCKED to ensure each job is processed exactly once. This pattern is used in background job systems like Que (Ruby), Graphile Worker (Node.js), and custom implementations built directly on PostgreSQL.
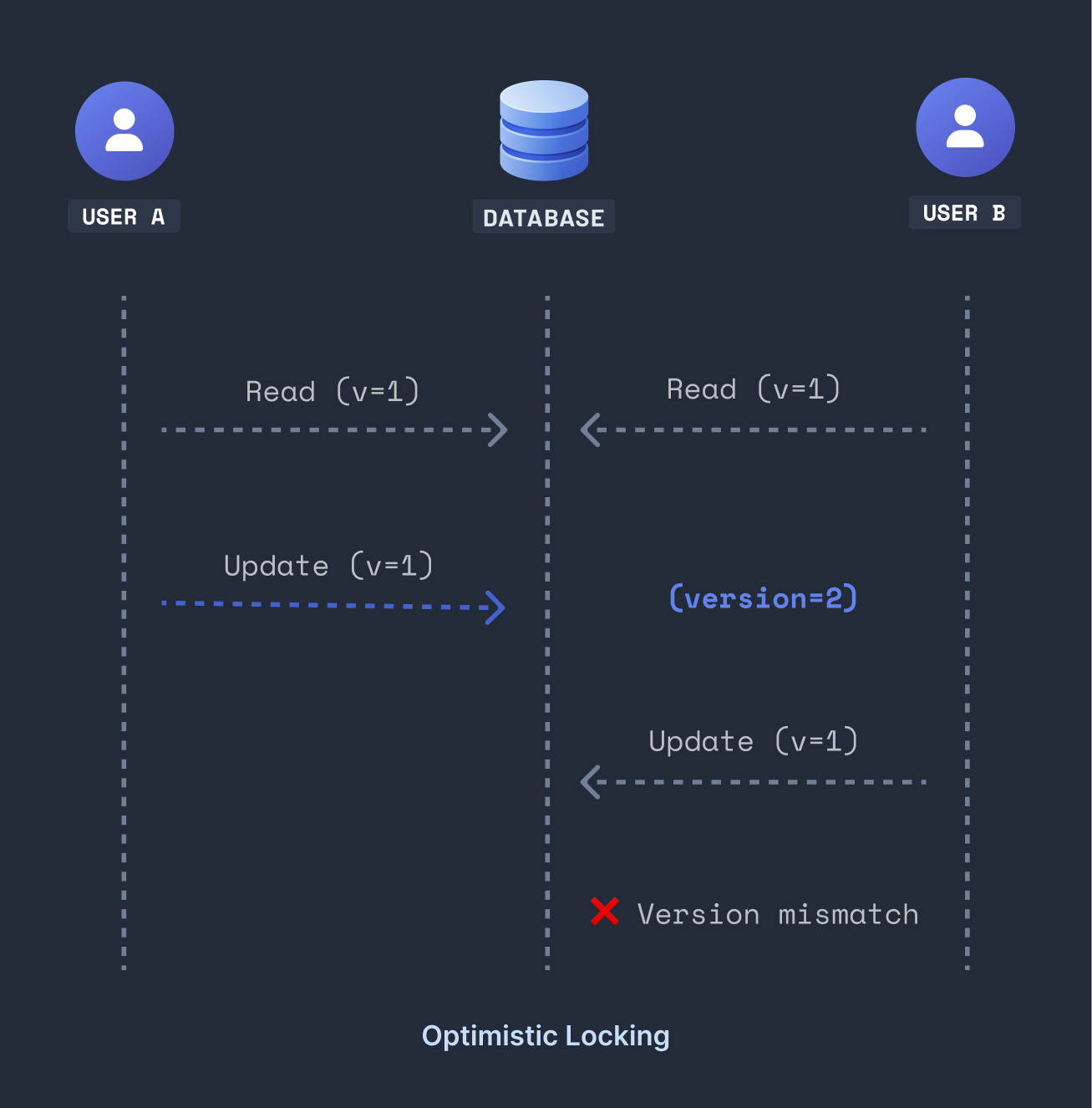
Optimistic Locking: Trust Everyone, Verify at the End
If pessimistic locking is a bouncer at the door, optimistic locking is an honour system with receipts. And once I understood that framing, the whole pattern made immediate sense.
Optimistic locking takes the opposite stance: conflicts are rare, so don’t block anyone. Let every transaction proceed freely. But before writing, verify that the data hasn’t changed since you read it. If it has, reject the write and let the application retry.
There’s no actual lock. The ‘locking’ is a version check: a simple integer column on your table that increments with every write.
Setting It Up in PostgreSQL
-- Add a version column to your table
ALTER TABLE tickets ADD COLUMN version INTEGER NOT NULL DEFAULT 1;Now every read includes the version, and every write checks it:
-- Step 1: Read with version
SELECT id, seat_number, status, version
FROM tickets
WHERE id = $1;
-- Returns: { id: 42, seat_number: 'A12', status: 'available', version: 7 }
-- Step 2: Write with version check
UPDATE tickets
SET status = 'booked',
version = version + 1 -- bump the version
WHERE id = $1
AND version = $2; -- only update if version hasn't changed
The key insight is result.rowCount. If it’s 1, your write succeeded: the version matched and no one else got in between. If it’s 0, someone else updated the row between your read and write. You re-read the fresh data and try again.
Auto-increment Version with a Trigger
If you don’t want your application layer to manage version bumps manually, let PostgreSQL handle it automatically:
CREATE OR REPLACE FUNCTION increment_version()
RETURNS TRIGGER AS $$
BEGIN
NEW.version = OLD.version + 1;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER auto_version
BEFORE UPDATE ON tickets
FOR EACH ROW EXECUTE FUNCTION increment_version();
Now every UPDATE automatically increments the version. Your application just needs to pass the version it read in the WHERE clause and check rowCount.
The Pitfalls
Optimistic locking breaks down under high contention. If 500 users are fighting over the same row simultaneously, most of them will get rowCount = 0 and retry, only to fail again. Retries pile up, creating what’s called a retry storm. Under sustained conflict, optimistic locking can actually perform worse than pessimistic locking because of all the wasted read-write cycles.
The other risk is not handling the conflict at all. If you don’t check rowCount and don’t retry, you silently drop the write and your user thinks their action succeeded when it didn’t.
Real-World Usage: Who Uses Optimistic Locking and Why
Optimistic locking thrives wherever users primarily work on their own data, and collisions are the exception rather than the rule.
Collaborative SaaS Tools (Notion, Linear, Jira)
When you edit a Notion page or update a Jira ticket, the system uses optimistic concurrency. Your changes are applied against the version you loaded. If a teammate edited the same field while you were typing, you’ll get a conflict notification rather than silently overwriting their work. Most of the time there’s no conflict at all: people work on different things. Blocking with pessimistic locks would be pure overhead for a near-zero collision rate.
E-Commerce Product Catalog and User Profiles
When a user updates their shipping address, profile photo, or preferences, that data is almost never contended: it’s theirs. Optimistic locking lets millions of users update their own records simultaneously with zero blocking. The version check adds negligible overhead while protecting against the rare edge case where a user has two sessions open and submits a form from both.
CMS and Content Publishing (WordPress, Contentful)
Content management systems use optimistic locking to prevent two editors from unknowingly overwriting each other’s drafts. When you open an article for editing, your session captures the version at that moment. If a colleague publishes an update while you’re still writing, your save fails with a conflict: prompting you to review their changes before proceeding. Blocking an entire document row for the duration of a writing session (potentially hours) would be impractical.
REST APIs and Mobile Applications
REST APIs are stateless by nature: you cannot hold a database lock across an HTTP request. Pessimistic locking simply doesn’t work for most REST patterns because the lock would need to span multiple requests and network round-trips. Optimistic locking is the natural fit: the client receives a version with the resource, includes it in the update request, and the server validates it before writing. This is the pattern used in AWS (ETag-based conditional updates), Stripe (idempotency keys + versioning), and most well-designed REST APIs.
How to Choose: A Practical Decision Framework
Most articles give you a vague ‘it depends.’ Here’s something more concrete. Ask yourself these four questions in order: your answer will almost always make the decision obvious:
Question 1: Are multiple users likely to target the exact same row at the same time?
Think about your data model. Is this a shared resource (a seat, a bank account, a limited inventory item) that many users compete for simultaneously? Or is it user-owned data that one person updates occasionally?
If shared and actively competed over → Pessimistic. Conflicts aren’t just possible, they’re expected. Lock it.
If user-owned or rarely contended → Continue to Question 2.
Question 2: Is a wrong write worse than a failed write?
In financial systems, selling the same seat twice, or debiting the wrong amount, can have legal and financial consequences. In a user profile update, a lost write is annoying but not catastrophic: the user just resubmits.
If correctness is non-negotiable → Pessimistic. A blocked transaction is safer than a wrong one.
If a retry is acceptable → Continue to Question 3.
Question 3: Does the operation span multiple HTTP requests or network calls?
Pessimistic locking requires holding a lock for the duration of a transaction. If your operation is a single database transaction that completes in milliseconds, that’s fine. But if the ‘transaction’ from the user’s perspective spans a form, a confirmation step, and a payment call, you cannot hold a database row lock across all of that.
If the operation spans multiple requests or takes seconds → Optimistic. You have no choice: pessimistic locking is architecturally incompatible.
If it’s a single fast transaction → Continue to Question 4.
Question 4: What does your read/write ratio look like?
If your table is read 1000 times for every 1 write, pessimistic locks create unnecessary contention: the vast majority of reads don’t need protection. If writes are frequent and reads are short, locking overhead is minimal.
If reads heavily dominate → Optimistic. Don’t penalise reads for writes that rarely happen.
If writes are frequent and fast → Either works. Default to Pessimistic for simplicity if contention is real.
Still unsure? Start with Optimistic and log your retry rates. If retries are consistently above 5-10% for a given operation, that’s your signal to switch that operation to Pessimistic. Don’t over-engineer upfront.
Here’s a summary of when each strategy wins:

Final Thoughts
Concurrency bugs are insidious. They’re invisible in unit tests, rare in staging, and catastrophic in production. The developers who understand locking are the ones who design systems that don’t silently lose money, double-sell inventory, or overbook seats.
When I first started learning system design, topics like this felt intimidating, like they belonged to a different tier of developer. But once I sat with it, the core idea is actually simple: two strategies, two assumptions about the world, each with a clear use case. The trick isn’t knowing the theory. It’s knowing when to reach for which one.
Pessimistic locks the row before reading. Optimistic checks the version before writing. PostgreSQL supports both natively. Your ORM probably abstracts both. And now you know what’s happening underneath.
Have you been bitten by a concurrency bug in production? Or are you just starting to think about this stuff? Either way, drop it in the comments: I read everything.
If this helped, follow along: I’m sharing everything I learn as I go deeper into system design and backend engineering.
Optimistic vs pessimistic locking usually sounds dry but this breakdown with examples and scenarios made it super clear. Curious what other approach others apply.